Sammanställ data med Pandas
Nu ska vi kika på hur man kan sammanställa stora datamängder i Python med hjälp av biblioteket Pandas.
Pandas är beroende av NumPy så du kommer att behöva även detta. Använder du
Debian eller Ubuntu så installerar du dessa båda paketen med följande kommando
apt-get install python3-numpy python3-pandas. När vi väl har installerat dessa
två bibliotek är det dags att börja gräva lite i hur Pandas fungerar.
Jag kommer visa med ett verkligt exempel här på hur jag sammanställer temperaturer i lägenheter. Temperaturen i vårt exempel har loggats vart femte minut, dygnet runt, under ca fem månaders tid. Därför har vi fått ganska mycket data. Datan är dessutom väldigt högupplöst. Det vi vill åstadkomma här är att få en veckoöversikt; det vill säga vi vill kunna presentera datan med medeltemperaturen för lägenheten per vecka. Vi kommer också att plotta denna data så att vi får en graf av det hela. Denna artikel kan därför ses som en fortsättning på Plotta sammansätt ränta i Python. Läs gärna igenom denna artikel först för att få en introduktion till Matplotlib.
Undersöka datan
Datan vi kommer att använda oss här är lghtemp.txt. Denna data ser ut som nedan.
Date Time Temperature
2016-02-07 03:25:02 22.2
2016-02-07 03:30:02 22.3
2016-02-07 03:35:03 22.3
2016-02-07 03:40:02 22.3
2016-02-07 03:45:02 22.3
2016-02-07 03:50:03 22.3
2016-02-07 03:55:03 22.4
2016-02-07 04:00:03 22.4
2016-02-07 04:05:03 22.4
Datan sträcker sig ända fram till 2016-06-28. Det är nu dags att försöka läsa in datan i Pandas, och tala om för Pandas vad som är vad i filen. Vi börjar med att skapa ett litet enkelt Pythonprogram för detta.
#!/usr/bin/env python3
import numpy as np
import pandas as pd
data = pd.read_csv("lghtemp.txt", sep=" ", parse_dates=['Date'])
print (data.head())
Här ovanför har vi grunden för vårt program som ska sammanställa datan åt oss i medelvärde per vecka. Men än så länge har vi inte kommit så långt, men dock en bra bit på vägen.
De första två raderna, import-raderna, talar om för Python att importera
biblioteken NumPy och Pandas samt att använda kortnamnen np och pd för
dessa.
Därefter på raden som börjar med data läser vi in temperaturdatan från filen
med pd.read_csv. Första argumentet är filnamnet. sep= " " talar om för
Pandas att varje kolumn i filen är åtskild med ett
mellanslag. parse_dates=['Date'] talar om för Pandas att kolumnen kallad
Date innehåller datum för raderna.
Den sista raden skriver ut de första fem raderna ur filen, tillsamman med rubrikerna för kolumnerna, samt en index-siffra som första kolumn. Utskriften ser ut så här.
Date Time Temperature
0 2016-02-07 03:25:02 22.2
1 2016-02-07 03:30:02 22.3
2 2016-02-07 03:35:03 22.3
3 2016-02-07 03:40:02 22.3
4 2016-02-07 03:45:02 22.3
Nu ser vi på formatering ovan att Pandas faktiskt förstår våra kolumner då den har formaterat om rubrikerna så att de nu är högerjusterade. Redan nu kan Pandas tolka vår data.
Sammanställa datan
Nu är det dags att gå vidare till att sammanställa datan så att vi istället får
ett medelvärde per vecka. Här måste vi alltså göra två saker. Steg ett blir att
vi måste försöka få in veckonumren i vår data och steg två blir att få fram
medelvärden för dessa veckor. Här räcker ju inte bara de enskilda dagarna, utan
vi måste få veckorna på något sätt. Pandas har faktiskt stöd för detta via dt
som är en förkortning av DateTime. Med detta skapar vi alltså en ny kolumn som
heter Week.
Vårt program har nu växt till att istället se ut som nedan.
#!/usr/bin/env python3
import numpy as np
import pandas as pd
data = pd.read_csv("lghtemp.txt", sep=" ", parse_dates=['Date'])
data['Week'] = data['Date'].dt.week
print (data.head())
Om vi nu kör ovanstående kod så kommer vi att se att vi har fått en kolumn som heter Week som visas här nedanför.
Date Time Temperature Week
0 2016-02-07 03:25:02 22.2 5
1 2016-02-07 03:30:02 22.3 5
2 2016-02-07 03:35:03 22.3 5
3 2016-02-07 03:40:02 22.3 5
4 2016-02-07 03:45:02 22.3 5
Nu när vi har fått in veckorna är det dags att fortsätta till steg två, nämligen
att få fram medeltemperaturen för dessa veckor. Detta är faktiskt inte mycket
svårare än det vi har gjort hittills. Här måste vi först gruppera in datan i
veckorna; för detta har vi Pandas egna groupby. Därefter skapar vi
medeltemperaturen med funktionen mean(). Vi utökar vår kod till följande.
#!/usr/bin/env python3
import numpy as np
import pandas as pd
data = pd.read_csv("lghtemp.txt", sep=" ", parse_dates=['Date'])
data['Week'] = data['Date'].dt.week
veckodata = data.groupby(['Week']) ['Temperature'].mean()
print (veckodata)
Om vi kör följande kod så kommer vi få medeltemperaturen för alla veckorna i en lista som visas här nedanför.
Week
5 22.251822
6 22.098222
7 21.737723
8 21.371974
9 20.941815
10 21.246329
11 21.983284
12 22.405289
13 23.102629
14 22.731895
15 22.822867
16 22.483978
17 22.742609
18 22.923413
19 23.551414
20 22.552083
21 23.419544
22 24.571032
23 23.447669
24 23.001984
25 23.700446
26 23.639919
Name: Temperature, dtype: float64
Plotta veckodatan
Nu när vi har lyckats få fram medeltemperaturen ur vår data så vill vi även plotta den i en graf. Detta är faktiskt det enklaste av allting.
Vi börjar med att importera Matplotlib och sedan är det bara att ange två
kommandon för att skapa själva grafen, nämligen plt.plot(veckodata) och
plt.show(). Hela programmet visas här nedanför.
#!/usr/bin/env python3
import matplotlib
matplotlib.use("Qt4Agg")
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data = pd.read_csv("lghtemp.txt", sep=" ", parse_dates=['Date'])
data['Week'] = data['Date'].dt.week
veckodata = data.groupby(['Week']) ['Temperature'].mean()
plt.plot(veckodata)
plt.show()
Om vi kör ovanstående program så kommer vi få ut en graf som visas här nedanför.
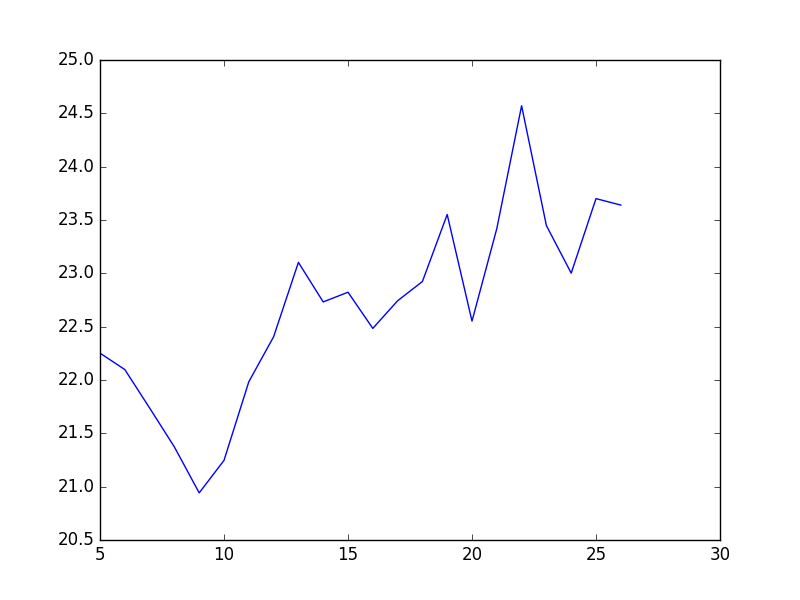
På detta sätt kan vi sammanställa och plotta stora datamängder med hjälp av Python och biblioteken Pandas, NumPy och Matplotlib – dessutom mycket enklare än att använda ett kalkylarksprogram. Den som har förkunskaper i till exempel MySQL känner säkert igen groupby och liknande från Pandas.
Uppdatering med Seaborn (2016-07-20)
För att få graferna att se lite vackrare ut, både på skärmen och på papper vid utskrifter, finns det ett utmärkt bibliotek för detta, nämligen Seaborn. Med Seaborn kan man ändra hur graferna ser ut. Till och med standardvärdena för Seaborn gör att graferna ser bättre ut.
Installera och testa Seaborn
På Debian-baserade system installeras Seaborn enklast med pip3, Pythons egna
installationsverktyg. Har du inte redan pip3 installerar du detta med apt-get
install python3-pip. Därefter installerar du seaborn med kommandot
pip3 install seaborn.
Nu när vi har installerat Seaborn kan vi ladda in det i vårt program. Vi fortsätter med koden vi hade tidigare där vi tog fram vår graf. Nu testar vi först med att bara importera Seaborn och ser direkt skillnad i grafens utseende.
#!/usr/bin/env python3
import matplotlib
matplotlib.use("Qt4Agg")
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
data = pd.read_csv("lghtemp.txt", sep=" ", parse_dates=['Date'])
data['Week'] = data['Date'].dt.week
veckodata = data.groupby(['Week']) ['Temperature'].mean()
plt.plot(veckodata)
plt.show()
Om vi kör detta programmet nu så får vi nedanstående graf, som redan nu ser bättre ut. Vi har bland annat stödlinjer, färger som är lättare för ögonen, andra typsnitt med mera. Allt detta bara genom att importera Seaborn.
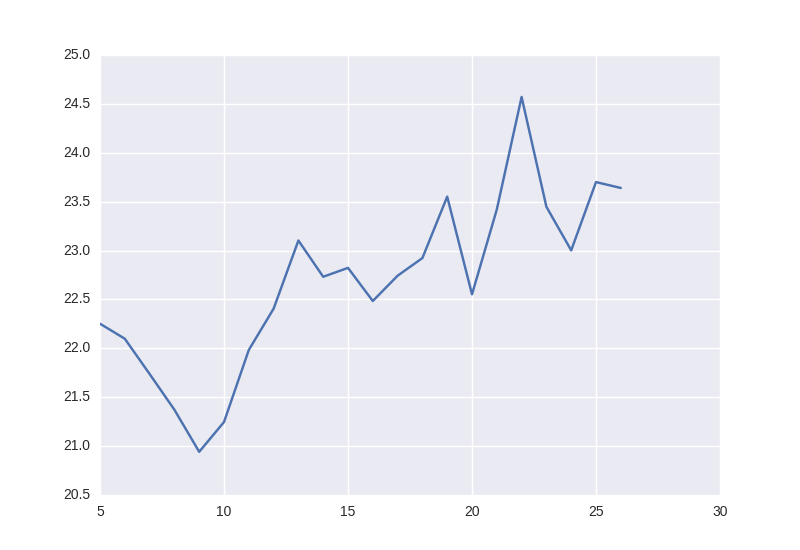
Ändra utseende med Seaborn
Men med Seaborn, tillsammans med Matplotlib, kan vi ändra utseendet ännu mer. Titta på koden här nedanför och testkör den så får du se verklig skillnad i resultat.
Här ändrar vi bakgrunden igen så att den blir helt vit, fast med stödlinjer. Vi
använder oss också av mallen paper för Seaborn för att förbättra
utskriftkvalitén på grafen. Därefter sätter vi våra egna typsnitt för
grafen. Med hjälp Matplotlib lägger vi dessutom till text för både x- och
y-axeln med plt.xlabel och plt.ylabel.
#!/usr/bin/env python3
import matplotlib
matplotlib.use("Qt4Agg")
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_context("paper")
sns.set(font='serif')
sns.set_style("whitegrid", {
"font.family": "serif",
"font.serif": ["Times", "Liberation", "serif"]
})
data = pd.read_csv("lghtemp.txt", sep=" ", parse_dates=['Date'])
data['Week'] = data['Date'].dt.week
veckodata = data.groupby(['Week']) ['Temperature'].mean()
plt.ylabel("Temperatur")
plt.xlabel("Vecka")
plt.plot(veckodata)
plt.show()
Utav denna kod får vi nedanstående graf, som är både mer lättläst, mjukare för ögonen och helt enkelt snyggare än den graf vi fick från början.
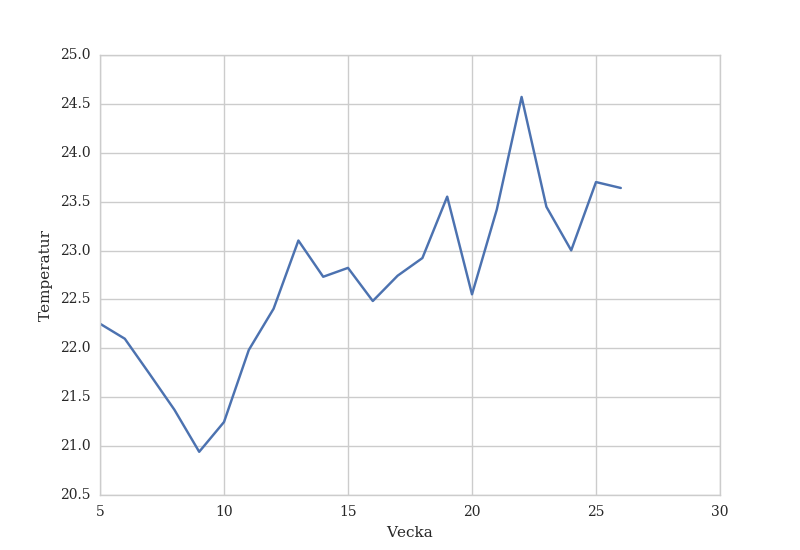
ANNONS FÖR VÅRA EGNA BÖCKER

Nyhetsbrev
Nyhetsuppdateringar från tidningen direkt till din inkorg, helt kostnadsfritt. Avsluta när du vill.
Relaterade artiklar
-
Skapa fristående binärer av Python-skript

Docker har blivit det nya sättet att paketera och köra Python-skript, även när skripten körs från exempelvis ett cronjob. Men ibland behöver vi inte en hel Docker-miljö med den overhead det innebär för väldigt små skript. Då är det smidigare att göra om skriptet till en körbar binärfil. Då kan vi även enkelt flytta filen mellan olika Linuxsystem.
-
Hämta data från API:er med cURL och jq

Med cURL och jq går det att extrahera data från API:er direkt från kommandoraden. Jq är en JSON-tolkare och beskrivs av utvecklarna som sed och awk för JSON.
-
Pythonmiljö i Docker

Ett vanligt användningsområde för Docker är att skapa och köra virtuella Pythonmiljöer. Med en Dockerfile och Docker Compose kan vi automatisera hela processen, från skapandet av miljön till exekveringen.
-
Python och trigonometri

Lite uppfräschning av trigonometri och Python är aldrig fel. Här får vi lära oss hur man kan rita upp rätvinkliga trianglar – direkt i Python – om vi känner till två av sidorna. För detta kommer vi att använda modulerna turtle och math.
-
Python i Windows utan installation

Det går att använda Python i Windows, även utan att installera det. Detta är användbart om du har en dator där du inte har rättigheter att installera program. Det kan till exempel vara en skoldator eller arbetsdator.
Senaste nyheterna och inläggen
-
Sätt upp en egen IRC-server på darknet
Rätten att kommunicera säkert är i fara. Just nu finns flertalet lagförslag som på ett eller annat sätt är tänkta att kringgå totalsträckskryptering. Det är således dags att hitta alternativ till de vanliga kanalerna ifall lagförslagen går igenom. Ett sådant alternativ är att gömma sig på Tor-nätverket, eller darknet som det också kallas.
-
En titt på OPAL2 och SEDutil
Många SSD stödjer idag något som heter OPAL2, en uppsättning specifikationer för hårddiskar och SSD. I specifikationerna ingår kryptering av diskar. Denna kryptering kan vi använda med verktyget SEDutil. SED i detta sammanhang står för Self-Encrypting Drive.
-
CyberInfo lämnar GitHub

CyberInfo har aldrig varit speciellt beroende av amerikanska tjänster. Men vi har använt oss av bland annat Amazon AWS i mindre utsträckning, samt GitHub för en stor del av kodförråden. Med tanke på det rådande geopolitiska läget har det blivit hög tid att lämna alla amerikanska tjänster.
-
Pågadata och en titt tillbaka

I år blev det inget reportage från Pågadata. Istället blev det en stilla närvaro med reflektioner kring demoscenen.
-
GrapheneOS – mer än bara ett säkert mobil-OS

GrapheneOS är ett operativsystem för Google Pixel-telefoner baserat på Android men utvecklat helt fristående från Google. Det är ett renare och betydligt säkrare system än vanliga Android.
Utvalda artiklar
-
Mysig stämning på sommarens första demoparty

I helgen var det Reunion 2024 i Kvidinge Folkets hus, sommarens första skånska demoparty. Partyt organiserades av Jesper “Skuggan” Klingvall. På plats fanns ett 30-tal besökare.
-
Datorparty i Landskrona

I helgen höll Syntax Society sitt årliga sommarparty. Platsen var en källarlokal i Landskrona där ett femtontal personer medverkade.
-
Det första Pågadata har ägt rum

I helgen ägde det första Pågadata rum – uppföljaren till Gubbdata. Platsen var Folkets Hus i Kvidinge. Organisatör av partyt var Johan “z-nexx” Osvaldsson med hjälp från Jesper “Skuggan” Klingvall. Partyt hade över 100 anmälda deltagare.
-
Även hovrätten fäller poliserna för att ha satt dit oskyldig

Hovrätten fastställer straffet för de två poliser som förra året dömdes till vardera ett års fängelse av Lunds tingsrätt för att ha misshandlat och satt dit en oskyldig man. De båda poliserna ska även betala skadestånd till mannen.
-
Retroloppis i Påarp

Idag var det retroloppis hos Andreas Nilsson i Påarp. På baksidan av huset fanns hundratals spel uppradade på långa bord. Trots friska vindar och sval temperatur var loppisen välbesökt.